Magic isn’t real
Any sufficiently advanced technology is indistinguishable from magic.

This will begin a series of posts about some of the more confusing or easily misunderstood topics in (linux) systems programming.
As part of a few potential upcoming opportunities to volunteer teaching, I’m going to talk about some topics that were slightly confusing to me for a while, that I think may be helpful to either newer developers, or just web developers who might be interested in moving towards the systems space. Be aware that this post is geared towards beginners, so there is some details and complexity left out.
Being completely self-taught, I often find myself thinking “damn, I wish someone would have just explained it to me like that”. So I hope to do that for someone else.
The first topic I want to discuss is Processes, not because I believe they are particularly misunderstood, or confusing really, but because they are fundamental to understanding the rest of the topics that I want to cover.
In fact, I originally started writing this post about pipes, but it quickly became clear that we must first be sure that we fully understand processes.
Doubtless, most developers would likely answer:
And some might think about it roughly something like this pseudo++
class Program {
unsigned int pid;
char data[14] = "Hello, world!\n";
public:
Program(unsigned int pid) : pid(pid) {}
void run() {
// do something with data
std::cout << data << '\n';
}
};
int main() {
auto process = new Program(1);
// we can imagine that now our Program is instantiated, it becomes a process
process->run();
return 0;
}
// NOTE:: Real processes are far more complex, they are executed in kernelspace with `fork`, `exec`, and `wait` syscalls
The first thing that we must remember, is that much like the code above, we are really discussing abstractions in the Kernel and sometimes it is important to distinguish this (Especially when we discuss threads in a later post). A process is simply an object (struct) in the kernel, that abstracts some resources, representing a running instance of a program.
If we imagine what kinds of data the kernel would need to store about a process, each would need to have an identifier (a PID or Process ID, as you may have seen running htop or ps aux) to distinguish between different processes.
It would also need to store data about the memory the process is using (because remember, the kernel allocates virtual, “mapped” memory for processes, not physical hardware memory addresses, so it must keep track of who is holding onto what).
Because the kernel is responsible for scheduling and managing the execution of each of these processes, there is also the Process Control Block.
First, let’s look at the struct that is representing a process in the kernel. This is a piece of the task_struct found in the linux kernel. Tip: we can use the pahole -C task_struct command on linux to see the layout of the task_struct in the kernel.
struct task_struct {
struct thread_info thread_info;
unsigned int __state;
unsigned int saved_state;
void * stack;
refcount_t usage;
unsigned int flags;
// ...
There is a lot to unpack here, but for now we’ll just focus on a couple fields.
The kernel needs to store the values of each of our processes set of saved registers,
so each process has an entry in the kernels process table which contains the PID
and the Process Control Block (PCB).
| Process Control Block | ||
|---|---|---|
| Program counter | The address of the next instruction to be executed | |
| Register values | The values of the registers of the process | |
| State | running, waiting, etc | |
| Priority | This is used by the kernel to schedule the process | |
| Address space | The memory the process is using | |
| Open Files | The files the process has open |
Let’s imagine that we have another pseudo program:
The following (well, all of it really) is a naive assumption for demonstration purposes, this should be obvious… but it is the internet after all
fn write_to_file() {
let mut f = File::create("file.txt");
f.write("Hello, world!")?;
f.close();
}
fn main() {
let foo = 32;
let bar = 23;
write_to_file(); // here, we are doing I/O a system call and will require a context switch
baz = foo + bar;
return baz
}
Say in our previous program (obviously assuming that this wasn’t inlined by the compiler), we had foo and bar in two different registers, but our program then calls write_to_file.
This will cause the kernel to have to perform tasks for us, here it is an I/O bound task. Any time your program requires switching between executing code for the user, then having to save the state of the current process before the kernel itself executes code, there is an opportunity for the kernels scheduler to make optimizations.
It is a fairly common misconception that a context switch is when the kernel switches between user mode and kernel mode. As we will see in a later example in assembly, this often times does in fact require a context switch, but a mode transition is not by itself, a context switch.
There may be many tasks waiting to be executed, and the kernel will need to keep track of all of these tasks, and the state of each of them. This is where the Process Control Block comes in.
The kernel might have to save the values of foo and bar in the Process Control Block and then move on to loading the values of f (file descriptor, buffer to write the data into, etc), and performing the I/O before it would switch back to the saved context and then compute baz from the content of the two registers.
Each process is given file descriptors by the kernel, stdin, stdout, and stderr, and each of these are represented as files. In a later post, this is where we will begin to discuss the concept of pipes and interprocess communication.
The stack field in the task struct is a pointer to where in the Kernel stack the process memory is stored, and the thread_info is an architecture-specific struct that contains information about the process, such as the pid and tgid (thread group id, we will discuss threads in the next post.)
If you have ever written any assembly (even a very small amount like myself), you might assume since you are responsible for managing the stack frame in your program, that each process has it’s own stack. This is true, but it is not the whole story.
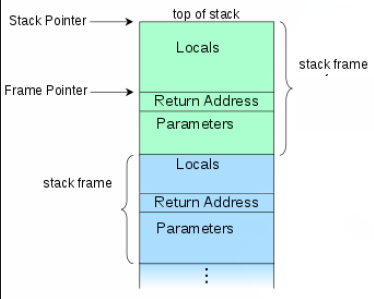
Example: This is a simple program that is semi analogous to our previous pseudo program
It is not expected that you understand assembly, so I will heavily comment each line. It is helpful to understand how CPU’s execute our code.
This demonstrates what is going on under the hood, and allows us to see where there will be context switching, as well as how we must manage the stack frame ourselves.
global _start
section .text
_start:
push rbp ; when our process starts, we have to push the value of the base (frame) pointer
; onto the stack (see: Return Address in the diagram above)
;this will allow us to access it later, when we need to clean up our stack frame and return control
mov rbp, rsp ; then we have to set the base pointer to the current stack pointer
; this is saying that the top of the existing stack is the beginning/bottom of our new stack frame
; now we have a stack frame(as pictured above), as the frame pointer points to the beginning of our stack frame, and the stack pointer points to the end
; now we are able to use the stack to store local variables and call functions
; (here we are just doing this for demonstration, as we have enough registers to use)
push 23 ; Second operand
push 32 ; First operand
; Pop operands into registers for multiplication
pop rax ; Pop first operand off the stack, into rax
pop rbx ; Pop second operand into rbx
mul rbx ; rax = rax * rbx, result is in rax
push rax ; Push result onto stack
; .. here we would be doing something with the result
mov rax, 1 ; syscall number for write
mov rdi, 1 ; file descriptor for stdout (the out pipe of our process)
mov rsi, message ; pointer to the message
mov rdx, len ; message length
; here it's possible that the kernel will schedule another process, and we will have to save our stack frame
syscall
; now we are done with the stack, we have to clean up
mov rsp, rbp ; set the stack pointer back to the frame pointer
pop rbp ; pop the frame pointer back off the stack, and back into rbp
mov rax, 60 ; syscall number for exit
xor rdi, rdi ; exit status 0 (xor with itself will always be 0)
syscall
section .data
message db "Hello, world!", 0xa
len equ $-message
As it turns out, there is in fact 1 stack frame per thread, instead of one per process.
This is how will begin the next topic of threads. Threads (and particularly async in general) was very confusing to me for some time.
How threads communicate, how they can access shared heap memory, and the difference between hardware, OS, and userspace threads (and how all of that relates to concepts like concurrency + Async/Await) is what we will discuss in the next post.
We’ll be looking at and comparing asynchronous programming in C, Rust and Go, and comparing the differences of implementation in each.
Now that we have a basic understanding of processes and how they are managed by the kernel, we can begin to look at how processes communicate with each other, and how they can share data. As much as I would like to get into my originally planned first post about pipes, we are going to have to tackle threads first which I believe will take at least a couple posts.
It is quite difficult to write a post that is both informative and concise, and inevitably I will have to sacrifice some details for general readability.
Note: I am certainly not claiming to be an expert in this, and if I am mistaken on any fundamental part of this post, please do let me know. I do plenty of research but I am not infallible, and I am always looking to learn more.
Any sufficiently advanced technology is indistinguishable from magic.
My story, and how this is all possible
(Modern) PHP: Does it really suck?
Processes, Pipes, I/O, Files and Threads/Async
Unsolicited advice for anyone seeking to learn computer science or software development in 2023.
How I got here is already far too long, so I must include a separate post for all the credits and gratitude I need to extend to those who made this possible.
Following up on the first impressions post, let’s solve a problem in OCaml and compare the Rust solution.
Humorous article, completely unrelated to, and written before, the others ended up actually on the front page.
OCaml: First impressions